commit
9889eb51ef
|
|
@ -0,0 +1,14 @@
|
|||
{
|
||||
"python.analysis.extraPaths": [
|
||||
"./src"
|
||||
],
|
||||
"python.testing.unittestArgs": [
|
||||
"-v",
|
||||
"-s",
|
||||
"./src",
|
||||
"-p",
|
||||
"test*.py"
|
||||
],
|
||||
"python.testing.pytestEnabled": false,
|
||||
"python.testing.unittestEnabled": true
|
||||
}
|
||||
|
|
@ -33,6 +33,10 @@ pip install music-kraken
|
|||
music-kraken
|
||||
```
|
||||
|
||||
## Dependencies
|
||||
- ffmpeg
|
||||
- pandoc
|
||||
|
||||
### Notes for Python 3.9
|
||||
|
||||
Unfortunately I use features that newly git introduced in [Python 3.10](https://docs.python.org/3/library/types.html#types.UnionType).
|
||||
|
|
|
|||
|
|
@ -0,0 +1,47 @@
|
|||
[build-system]
|
||||
requires = ["setuptools>=58.0.4", "wheel>=0.37.0"]
|
||||
build-backend = "setuptools.build_meta"
|
||||
|
||||
[project]
|
||||
name = "music-kraken"
|
||||
version = "1.2.1"
|
||||
description = "An extensive music downloader crawling the internet. It gets its metadata from a couple of metadata providers, and it scrapes the audiofiles."
|
||||
authors = [{ name = "Hellow2", email = "Hellow2@outlook.de" }]
|
||||
license = "AGPL-3.0-or-later"
|
||||
readme = "README.md"
|
||||
repository = "https://github.com/HeIIow2/music-downloader"
|
||||
requires-python = ">=3.10"
|
||||
classifiers = [
|
||||
"Development Status :: 4 - Beta",
|
||||
"Environment :: Console",
|
||||
"Intended Audience :: End Users/Desktop",
|
||||
"License :: OSI Approved :: GNU Affero General Public License v3 or later (AGPLv3+)",
|
||||
"Natural Language :: English",
|
||||
"Operating System :: OS Independent",
|
||||
"Programming Language :: Python :: 3.10",
|
||||
"Topic :: Multimedia :: Sound/Audio",
|
||||
"Topic :: Utilities",
|
||||
]
|
||||
[project.dependencies]
|
||||
requests = "~=2.28.1"
|
||||
mutagen = "~=1.46.0"
|
||||
musicbrainzngs = "~=0.7.1"
|
||||
jellyfish = "~=0.9.0"
|
||||
pydub = "~=0.25.1"
|
||||
youtube_dl = "*"
|
||||
beautifulsoup4 = "~=4.11.1"
|
||||
pycountry = "~=22.3.5"
|
||||
|
||||
|
||||
[tool.setuptools.entry_points]
|
||||
music-kraken = "music_kraken:cli"
|
||||
|
||||
[tool.setuptools]
|
||||
packages = ['music_kraken', 'music_kraken.lyrics', 'music_kraken.not_used_anymore', 'music_kraken.target', 'music_kraken.tagging', 'music_kraken.utils', 'music_kraken.not_used_anymore.sources', 'music_kraken.database', 'music_kraken.static_files']
|
||||
include_package_data = true
|
||||
package_dir = {''= 'src', 'music_kraken'= 'src/music_kraken'}
|
||||
package_data = {'music_kraken'= ['*.sql']}
|
||||
data_files = ["", ["requirements.txt", "README.md", "version"]]
|
||||
|
||||
[tool.setuptools.command.test]
|
||||
# ...
|
||||
|
|
@ -8,5 +8,5 @@ beautifulsoup4~=4.11.1
|
|||
pycountry~=22.3.5
|
||||
python-dateutil~=2.8.2
|
||||
pandoc~=2.3
|
||||
peewee~=3.15.4
|
||||
SQLAlchemy
|
||||
setuptools~=60.2.0
|
||||
|
|
@ -1,46 +1,62 @@
|
|||
Metadata-Version: 2.1
|
||||
Name: music-kraken
|
||||
Version: 1.2.2
|
||||
Summary: An extensive music downloader crawling the internet. It gets its metadata from a couple metadata provider, and it scrapes the audiofiles.
|
||||
Summary: An extensive music downloader crawling the internet. It gets its metadata from a couple of metadata providers, and it scrapes the audiofiles.
|
||||
Home-page: https://github.com/HeIIow2/music-downloader
|
||||
Author: Hellow2
|
||||
Author-email: Hellow2@outlook.de
|
||||
License: UNKNOWN
|
||||
Platform: UNKNOWN
|
||||
Description-Content-Type: text/markdown
|
||||
License-File: LICENSE
|
||||
|
||||
# Music Kraken
|
||||
# Music Kraken
|
||||
|
||||
<img align="right" src="assets/logo.svg" width=300>
|
||||
|
||||
1. [Installlation](#installation)
|
||||
2. [Command Line Usage](#quick-guide)
|
||||
3. [Library Usage / Python Interface](#programming-interface--use-as-library)
|
||||
4. [About Metadata](#metadata)
|
||||
5. [About the Audio](#download)
|
||||
6. [About the Lyrics](#lyrics)
|
||||
3. [Contribute](#contribute)
|
||||
4. [Matrix Space](#matrix-space), if you don't wanna read: **[Invite](https://matrix.to/#/#music-kraken:matrix.org)**
|
||||
|
||||

|
||||
5. [Library Usage / Python Interface](#programming-interface--use-as-library)
|
||||
6. [About Metadata](#metadata)
|
||||
7. [About the Audio](#download)
|
||||
8. [About the Lyrics](#lyrics)
|
||||
|
||||
---
|
||||
|
||||
## Installation
|
||||
|
||||
You can find and get this project from either [PyPI](https://pypi.org/project/music-kraken/) as Python-Package
|
||||
You can find and get this project from either [PyPI](https://pypi.org/project/music-kraken/) as a Python-Package,
|
||||
or simply the source code from [GitHub](https://github.com/HeIIow2/music-downloader). Note that even though
|
||||
everything **SHOULD** work cross Plattform, I only tested it on Ubuntu.
|
||||
If you enjoy this project, feel free to give it a Star on GitHub.
|
||||
everything **SHOULD** work cross-platform, I have only tested it on Ubuntu.
|
||||
If you enjoy this project, feel free to give it a star on GitHub.
|
||||
|
||||
```sh
|
||||
# install it with
|
||||
# Install it with
|
||||
pip install music-kraken
|
||||
|
||||
# and simply run it like this:
|
||||
music-kraken
|
||||
```
|
||||
|
||||
## Dependencies
|
||||
- ffmpeg
|
||||
- pandoc
|
||||
|
||||
### Notes for Python 3.9
|
||||
|
||||
Unfortunately I use features that newly git introduced in [Python 3.10](https://docs.python.org/3/library/types.html#types.UnionType).
|
||||
So unfortunately you **CAN'T** run this programm with python 3.9. [#10][i10]
|
||||
|
||||
### Notes for WSL
|
||||
|
||||
If you choose to run it in WSL, make sure ` ~/.local/bin` is added to your `$PATH` [#2][i2]
|
||||
|
||||
## Quick-Guide
|
||||
|
||||
**Genre:** First the cli asks you to input a gere you want to download to. The options it gives you (if it gives you any) are all the folders you got in the music directory. You also can just input a new one.
|
||||
**Genre:** First, the cli asks you to input a genre you want to download to. The options it gives you (if it gives you any) are all the folders you have in the music directory. You can also just input a new one.
|
||||
|
||||
**What to download:** After that it prompts you for a search. Here are a couple examples how you can search:
|
||||
|
||||
|
|
@ -55,18 +71,358 @@ searches for the release (album) <any release> by the artist <any artist>
|
|||
searches for the track <any track> from the release <any relaese>
|
||||
```
|
||||
|
||||
After searching with this syntax it prompts you with multiple results. You can either choose one of those by inputing its id `int` or you can search for a new query.
|
||||
After searching with this syntax, it prompts you with multiple results. You can either choose one of those by inputing its id `int`, or you can search for a new query.
|
||||
|
||||
After you chose either an artist, a release group, a release or a track by its id, download it by inputing the string `ok`. My downloader will download it automatically for you.
|
||||
After you chose either an artist, a release group, a release, or a track by its id, download it by inputting the string `ok`. My downloader will download it automatically for you.
|
||||
|
||||
---
|
||||
|
||||
## Programming Interface / use as Library
|
||||
## CONTRIBUTE
|
||||
|
||||
I am happy about every pull request. To contribute look [here](contribute.md).
|
||||
|
||||
## Matrix Space
|
||||
|
||||
<img align="right" src="assets/element_logo.png" width=100>
|
||||
|
||||
I decided against creating a discord server, due to piracy communities get often banned from discord. A good and free Alternative are Matrix Spaces. I reccomend the use of the Client [Element](https://element.io/download). It is completely open source.
|
||||
|
||||
**Click [this link](https://matrix.to/#/#music-kraken:matrix.org) _([https://matrix.to/#/#music-kraken:matrix.org](https://matrix.to/#/#music-kraken:matrix.org))_ to join.**
|
||||
|
||||
---
|
||||
|
||||
# Programming Interface / Use as Library
|
||||
|
||||
This application is $100\%$ centered around Data. Thus the most important thing for working with musik kraken is, to understand how I structured the data.
|
||||
|
||||
## quick Overview
|
||||
|
||||
- explanation of the [Data Model](#data-model)
|
||||
- how to use the [Data Objects](#data-objects)
|
||||
|
||||
```mermaid
|
||||
---
|
||||
title: Quick Overview
|
||||
---
|
||||
sequenceDiagram
|
||||
|
||||
participant pg as Page (eg. YouTube, MB, Musify, ...)
|
||||
participant obj as DataObjects (eg. Song, Artist, ...)
|
||||
participant db as DataBase
|
||||
|
||||
obj ->> db: write
|
||||
db ->> obj: read
|
||||
|
||||
pg -> obj: find a source for any page, for object.
|
||||
obj -> pg: add more detailed data from according page.
|
||||
obj -> pg: if available download audio to target.
|
||||
```
|
||||
|
||||
## Data Model
|
||||
|
||||
The Data Structure, that the whole programm is built on looks as follows:
|
||||
|
||||
```mermaid
|
||||
---
|
||||
title: Music Data
|
||||
---
|
||||
erDiagram
|
||||
|
||||
|
||||
|
||||
Target {
|
||||
|
||||
}
|
||||
|
||||
Lyrics {
|
||||
|
||||
}
|
||||
|
||||
Song {
|
||||
|
||||
}
|
||||
|
||||
Album {
|
||||
|
||||
}
|
||||
|
||||
Artist {
|
||||
|
||||
}
|
||||
|
||||
Label {
|
||||
|
||||
}
|
||||
|
||||
Source {
|
||||
|
||||
}
|
||||
|
||||
Source }o--|| Song : from
|
||||
Source }o--|| Lyrics : from
|
||||
Source }o--|| Album : from
|
||||
Source }o--|| Artist : from
|
||||
Source }o--|| Label : from
|
||||
|
||||
Song }o--o{ Album : AlbumSong
|
||||
Album }o--o{ Artist : ArtistAlbum
|
||||
Song }o--o{ Artist : features
|
||||
|
||||
Label }o--o{ Album : LabelAlbum
|
||||
Label }o--o{ Artist : LabelSong
|
||||
|
||||
Song ||--o{ Lyrics : contains
|
||||
Song ||--o{ Target : points
|
||||
```
|
||||
|
||||
Ok now this **WILL** look intimidating, thus I break it down quickly.
|
||||
*That is also the reason I didn't add all Attributes here.*
|
||||
|
||||
The most important Entities are:
|
||||
|
||||
- Song
|
||||
- Album
|
||||
- Artist
|
||||
- Label
|
||||
|
||||
All of them *(and Lyrics)* can have multiple Sources, and every Source can only Point to one of those Element.
|
||||
|
||||
The `Target` Entity represents the location on the hard drive a Song has. One Song can have multiple download Locations.
|
||||
|
||||
The `Lyrics` Entity simply represents the Lyrics of each Song. One Song can have multiple Lyrics, e.g. Translations.
|
||||
|
||||
Here is the simplified Diagramm without only the main Entities.
|
||||
|
||||
|
||||
```mermaid
|
||||
---
|
||||
title: simplified Music Data
|
||||
---
|
||||
erDiagram
|
||||
|
||||
Song {
|
||||
|
||||
}
|
||||
|
||||
Album {
|
||||
|
||||
}
|
||||
|
||||
Artist {
|
||||
|
||||
}
|
||||
|
||||
Label {
|
||||
|
||||
}
|
||||
|
||||
Song }o--o{ Album : AlbumSong
|
||||
Album }o--o{ Artist : ArtistAlbum
|
||||
Song }o--o{ Artist : features
|
||||
|
||||
Label }o--o{ Album : LabelAlbum
|
||||
Label }o--o{ Artist : LabelSong
|
||||
|
||||
```
|
||||
|
||||
Looks way more manageable, doesn't it?
|
||||
|
||||
The reason every relation here is a `n:m` *(many to many)* relation is not, that it makes sense in the aspekt of modeling reality, but to be able to put data from many Sources in the same Data Model.
|
||||
Every Service models Data a bit different, and projecting a one-to-many relationship to a many to many relationship without data loss is easy. The other way around it is basically impossible
|
||||
|
||||
## Data Objects
|
||||
|
||||
> Not 100% accurate yet and *might* change slightly
|
||||
|
||||
### Creation
|
||||
|
||||
```python
|
||||
# importing the libraries I build on
|
||||
from music_kraken import objects
|
||||
|
||||
import pycountry
|
||||
|
||||
|
||||
song = objects.Song(
|
||||
genre="HS Core",
|
||||
title="Vein Deep in the Solution",
|
||||
length=666,
|
||||
isrc="US-S1Z-99-00001",
|
||||
tracksort=2,
|
||||
target=[
|
||||
objects.Target(file="song.mp3", path="example")
|
||||
],
|
||||
lyrics_list=[
|
||||
objects.Lyrics(text="these are some depressive lyrics", language="en"),
|
||||
objects.Lyrics(text="Dies sind depressive Lyrics", language="de")
|
||||
],
|
||||
source_list=[
|
||||
objects.Source(objects.SourcePages.YOUTUBE, "https://youtu.be/dfnsdajlhkjhsd"),
|
||||
objects.Source(objects.SourcePages.MUSIFY, "https://ln.topdf.de/Music-Kraken/")
|
||||
],
|
||||
album_list=[
|
||||
objects.Album(
|
||||
title="One Final Action",
|
||||
date=objects.ID3Timestamp(year=1986, month=3, day=1),
|
||||
language=pycountry.languages.get(alpha_2="en"),
|
||||
label_list=[
|
||||
objects.Label(name="an album label")
|
||||
],
|
||||
source_list=[
|
||||
objects.Source(objects.SourcePages.ENCYCLOPAEDIA_METALLUM, "https://www.metal-archives.com/albums/I%27m_in_a_Coffin/One_Final_Action/207614")
|
||||
]
|
||||
),
|
||||
],
|
||||
main_artist_list=[
|
||||
objects.Artist(
|
||||
name="I'm in a coffin",
|
||||
source_list=[
|
||||
objects.Source(
|
||||
objects.SourcePages.ENCYCLOPAEDIA_METALLUM,
|
||||
"https://www.metal-archives.com/bands/I%27m_in_a_Coffin/127727"
|
||||
)
|
||||
]
|
||||
),
|
||||
objects.Artist(name="some_split_artist")
|
||||
],
|
||||
feature_artist_list=[
|
||||
objects.Artist(
|
||||
name="Ruffiction",
|
||||
label_list=[
|
||||
objects.Label(name="Ruffiction Productions")
|
||||
]
|
||||
)
|
||||
],
|
||||
)
|
||||
|
||||
print(song.option_string)
|
||||
for album in song.album_collection:
|
||||
print(album.option_string)
|
||||
for artist in song.main_artist_collection:
|
||||
print(artist.option_string)
|
||||
```
|
||||
|
||||
|
||||
|
||||
If you just want to start implementing, then just use the code example, I don't care.
|
||||
For those who don't want any bugs and use it as intended *(which is recommended, cuz I am only one person so there are defs bugs)* continue reading.
|
||||
|
||||
## Appending and Merging data
|
||||
|
||||
If you want to append for example a Song to an Album, you obviously need to check beforehand if the Song already exists in the Album, and if so, you need to merge their data in one Song object, to not loose any Information.
|
||||
|
||||
Fortunately I implemented all of this functionality in [objects.Collection](#collection).append(music_object).
|
||||
I made a flow chart showing how it works:
|
||||
|
||||
```mermaid
|
||||
---
|
||||
title: "Collection.append(music_object: MusicObject)"
|
||||
---
|
||||
flowchart TD
|
||||
exist("""
|
||||
<b>Check if music_object already exists.</b>
|
||||
<hr>
|
||||
Gets all indexing values with <code>music_object.indexing_values</code>.
|
||||
If any returned value exists in <code>Collection._attribute_to_object_map</code>,
|
||||
the music_object exists
|
||||
""")
|
||||
|
||||
subgraph merge["Merging"]
|
||||
|
||||
_merge("""merges the passed in object in the already
|
||||
existing whith <code>existing.merge(new)</code>""")
|
||||
|
||||
_map("""In case a new source or something simmilar
|
||||
has been addet, it maps the existing object again.
|
||||
""")
|
||||
|
||||
_merge --> _map
|
||||
|
||||
end
|
||||
|
||||
subgraph add["Adding"]
|
||||
|
||||
__map("""map the values from <code>music_object.indexing_values</code>
|
||||
to <code>Collection._attribute_to_object_map</code> by writing
|
||||
those values in the map as keys, and the class I wanna add as values.
|
||||
""")
|
||||
|
||||
_add("""add the new music object to <code>_data</code>""")
|
||||
|
||||
__map --> _add
|
||||
|
||||
end
|
||||
|
||||
exist-->|"if it doesn't exist"|add --> return
|
||||
exist-->|"if already exists"|merge --> return
|
||||
```
|
||||
|
||||
This is Implemented in [music_kraken.objects.Collection.append()](src/music_kraken/objects/collection.py).
|
||||
|
||||
The <u>indexing values</u> are defined in the superclass [DatabaseObject](src/music_kraken/objects/parents.py) and get implemented for each Object seperately. I will just give as example its implementation for the `Song` class:
|
||||
|
||||
```python
|
||||
@property
|
||||
def indexing_values(self) -> List[Tuple[str, object]]:
|
||||
return [
|
||||
('id', self.id),
|
||||
('title', self.unified_title),
|
||||
('barcode', self.barcode),
|
||||
*[('url', source.url) for source in self.source_collection]
|
||||
]
|
||||
```
|
||||
|
||||
## Classes and Objects
|
||||
|
||||
### music_kraken.objects
|
||||
|
||||
#### Collection
|
||||
|
||||
#### Song
|
||||
|
||||
So as you can see, the probably most important Class is the `music_kraken.Song` class. It is used to save the song in *(duh)*.
|
||||
|
||||
It has handful attributes, where half of em are self-explanatory, like `title` or `genre`. The ones like `isrc` are only relevant to you, if you know what it is, so I won't elaborate on it.
|
||||
|
||||
Interesting is the `date`. It uses a custom class. More on that [here](#music_krakenid3timestamp).
|
||||
|
||||
#### ID3Timestamp
|
||||
|
||||
For multiple Reasons I don't use the default `datetime.datetime` class.
|
||||
|
||||
The most important reason is, that you need to pass in at least year, month and day. For every other values there are default values, that are indistinguishable from values that are directly passed in. But I need optional values. The ID3 standart allows default values. Additionally `datetime.datetime` is immutable, thus I can't inherint all the methods. Sorry.
|
||||
|
||||
Anyway you can create those custom objects easily.
|
||||
|
||||
```python
|
||||
from music_kraken import ID3Timestamp
|
||||
|
||||
# returns an instance of ID3Timestamp with the current time
|
||||
ID3Timestamp.now()
|
||||
|
||||
# yea
|
||||
ID3Timestamp(year=1986, month=3, day=1)
|
||||
```
|
||||
|
||||
you can pass in the Arguments:
|
||||
- year
|
||||
- month
|
||||
- day
|
||||
- hour
|
||||
- minute
|
||||
- second
|
||||
|
||||
:)
|
||||
|
||||
# Old implementation
|
||||
|
||||
> IF U USE THIS NOW YOU ARE DUMB *no offense thoug*. IT ISN'T FINISHED AND THE STUFF YOU CODE NOW WILL BE BROKEN TOMORROW
|
||||
> SOON YOU CAN THOUGH
|
||||
|
||||
If you want to use this project, or parts from it in your own projects from it,
|
||||
make sure to be familiar with [Python Modules](https://docs.python.org/3/tutorial/modules.html).
|
||||
Further and better documentation including code examples are yet to come, so here is the rough
|
||||
module structure for now. (should be up-to-date but no guarantee)
|
||||
module structure for now. (Should be up-to-date, but no guarantees)
|
||||
|
||||
If you simply want to run the builtin minimal cli just do this:
|
||||
```python
|
||||
|
|
@ -77,15 +433,15 @@ cli()
|
|||
|
||||
### Search for Metadata
|
||||
|
||||
The whole programm takes the data it processes further from the cache, a sqlite database.
|
||||
The whole program takes the data it processes further from the cache, a sqlite database.
|
||||
So before you can do anything, you will need to fill it with the songs you want to download (*or create song objects manually, but more on that later*).
|
||||
|
||||
For now the base of everything is [musicbrainz][mb], so you need to get the musicbrainz `id` and `type` the id corresponds to either
|
||||
For now the base of everything is [musicbrainz][mb], so you need to get the musicbrainz `id` and `type`. The `id` corresponds to either
|
||||
- an artist
|
||||
- a release group
|
||||
- a release
|
||||
- a recording/track).
|
||||
|
||||
|
||||
To get this info, you first have to initialize a search object (`music_kraken.MetadataSearch`).
|
||||
|
||||
```python
|
||||
|
|
@ -102,7 +458,7 @@ multiple_options = search_object.search_from_text(artist=input("input the name o
|
|||
multiple_options = search_object.search_from_query(query=input("input the query: "))
|
||||
```
|
||||
|
||||
both possible methods return an instance of `MultipleOptions`, which can be directly converted to a string.
|
||||
Both methods return an instance of `MultipleOptions`, which can be directly converted to a string.
|
||||
|
||||
```python
|
||||
print(multiple_options)
|
||||
|
|
@ -166,7 +522,7 @@ have following values:
|
|||
- 'release'
|
||||
- 'recording'
|
||||
|
||||
**PAY ATTENTION TO TYPOS, ITS CASE SENSITIVE**
|
||||
**PAY ATTENTION TO TYPOS, IT'S CASE SENSITIVE**
|
||||
|
||||
The musicbrainz id is just the id of the object from musicbrainz.
|
||||
|
||||
|
|
@ -179,7 +535,7 @@ All the data, the functions that download stuff use, can be gotten from the temp
|
|||
The cache can be simply used like this:
|
||||
|
||||
```python
|
||||
music_kraken.cache
|
||||
music_kraken.test_db
|
||||
```
|
||||
|
||||
When fetching any song data from the cache, you will get it as Song
|
||||
|
|
@ -200,7 +556,7 @@ cache.get_tracks_without_isrc()
|
|||
cache.get_tracks_without_filepath()
|
||||
```
|
||||
|
||||
the id always is a musicbrainz id and distinct for every track.
|
||||
The id always is a musicbrainz id and distinct for every track.
|
||||
|
||||
### Setting the Target
|
||||
|
||||
|
|
@ -213,13 +569,13 @@ from music_kraken import set_target
|
|||
set_target(genre="some test genre")
|
||||
```
|
||||
|
||||
The concept of genres is too loose, to definitly say, this band exclusively plays this genre, or this song is this genre. This doesn't work manually, this will never work automatically. Thus I've decided to just use the genre as category, to sort the artists and songs by. Most Music players support that.
|
||||
The concept of genres is too loose, to definitely say, this band exclusively plays this genre, or this song is this genre. This doesn't work manually, this will never work automatically. Thus, I've decided to just use the genre as category, to sort the artists and songs by. Most Music players support that.
|
||||
|
||||
As a result of this decision you will have to pass the genre in this function.
|
||||
|
||||
### Get Audio
|
||||
|
||||
This is most likely the most usefull and unique feature of this Project. If the cache is filled you can get audio sources for the songs you only have the metadata, and download them. This works for most songs. I'd guess for about 97% (?)
|
||||
This is most likely the most useful and unique feature of this Project. If the cache is filled, you can get audio sources for the songs you only have the metadata, and download them. This works for most songs. I'd guess for about 97% (?)
|
||||
|
||||
First of you will need a List of song objects `music_kraken.Song`. As [mentioned above](#cache--temporary-database), you could get a list like that from the cache.
|
||||
|
||||
|
|
@ -254,15 +610,15 @@ First the metadata has to be downloaded. The best api to do so is undeniably [Mu
|
|||
|
||||
|
||||
|
||||
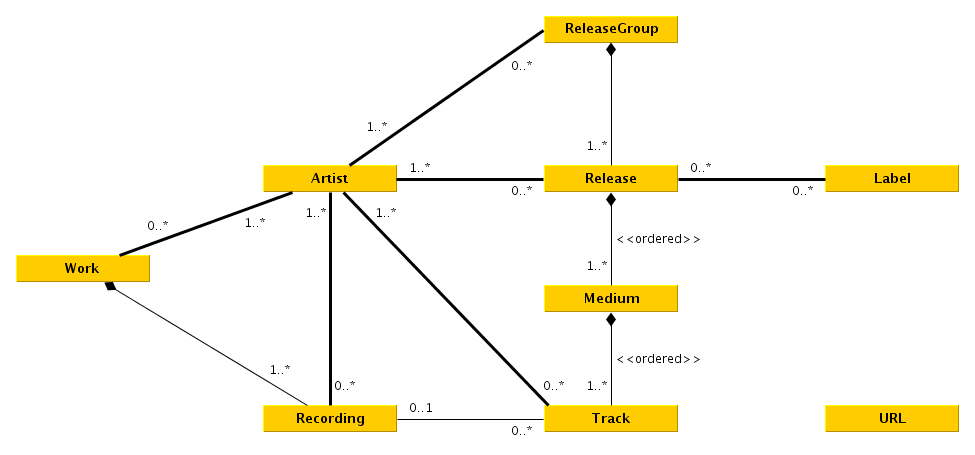
To fetch from [Musicbrainz][mb] we first have to know what to fetch. A good start is to get an input querry, which can be just put into the MB-Api. It then returns a list of possible artists, releases and recordings.
|
||||
To fetch from [Musicbrainz][mb] we first have to know what to fetch. A good start is to get an input query, which can be just put into the MB-Api. It then returns a list of possible artists, releases and recordings.
|
||||
|
||||
If the following chosen element is an artist, its discography + a couple tracks are printed, if a release is chosen, the artists + tracklist + release is outputted, If a track is chosen its artists and releases are shown.
|
||||
|
||||
Up to now it doesn't if the discography or tracklist is chosen.
|
||||
For now, it doesn't if the discography or tracklist is chosen.
|
||||
|
||||
### Metadata to fetch
|
||||
|
||||
I orient on which metadata to download on the keys in `mutagen.EasyID3` . Following I fetch and thus tag the MP3 with:
|
||||
I orient on which metadata to download on the keys in `mutagen.EasyID3`. The following I fetch and tag the MP3 with:
|
||||
- title
|
||||
- artist
|
||||
- albumartist
|
||||
|
|
@ -293,7 +649,7 @@ Now that the metadata is downloaded and cached, download sources need to be soun
|
|||
|
||||
### Musify
|
||||
|
||||
The quickest source to get download links from is to my knowledge [musify](https://musify.club/). Its a russian music downloading page, where many many songs are available to stream and to download. Due to me not wanting to stress the server to much, I abuse a handy feature nearly every page where you can search suff has. The autocomplete api for the search input. Those always are quite limited in the number of results it returns, but it is optimized to be quick. Thus with the http header `Connection` set to `keep-alive` the bottleneck defently is not at the speed of those requests.
|
||||
The quickest source to get download links from is to my knowledge [musify](https://musify.club/). It's a Russian music downloading page, where many many songs are available to stream and to download. Due to me not wanting to stress the server to much, I abuse a handy feature nearly every page where you can search suff has. The autocomplete api for the search input. Those always are quite limited in the number of results it returns, but it is optimized to be quick. Thus with the http header `Connection` set to `keep-alive` the bottleneck definitely is not at the speed of those requests.
|
||||
|
||||
For musify the endpoint is following: [https://musify.club/search/suggestions?term={title}](https://musify.club/search/suggestions?term=LornaShore) If the http headers are set correctly, then searching for example for "Lorna Shore" yields following result:
|
||||
|
||||
|
|
@ -341,5 +697,8 @@ To get the Lyrics, I scrape them, and put those in the USLT ID3 Tags of for exam
|
|||
For the lyrics source the page [https://genius.com/](https://genius.com/) is easily sufficient. It has most songs. Some songs are not present though, but that is fine, because the lyrics are optional anyways.
|
||||
|
||||
|
||||
[i10]: https://github.com/HeIIow2/music-downloader/issues/10
|
||||
[i2]: https://github.com/HeIIow2/music-downloader/issues/2
|
||||
[mb]: https://musicbrainz.org/
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -1,5 +1,6 @@
|
|||
LICENSE
|
||||
README.md
|
||||
pyproject.toml
|
||||
requirements.txt
|
||||
setup.py
|
||||
version
|
||||
|
|
@ -13,35 +14,33 @@ src/music_kraken.egg-info/dependency_links.txt
|
|||
src/music_kraken.egg-info/entry_points.txt
|
||||
src/music_kraken.egg-info/requires.txt
|
||||
src/music_kraken.egg-info/top_level.txt
|
||||
src/music_kraken/audio_source/__init__.py
|
||||
src/music_kraken/audio_source/fetch_audio.py
|
||||
src/music_kraken/audio_source/fetch_source.py
|
||||
src/music_kraken/audio_source/sources/__init__.py
|
||||
src/music_kraken/audio_source/sources/local_files.py
|
||||
src/music_kraken/audio_source/sources/musify.py
|
||||
src/music_kraken/audio_source/sources/source.py
|
||||
src/music_kraken/audio_source/sources/youtube.py
|
||||
src/music_kraken/database/__init__.py
|
||||
src/music_kraken/database/artist.py
|
||||
src/music_kraken/database/data_models.py
|
||||
src/music_kraken/database/database.py
|
||||
src/music_kraken/database/metadata.py
|
||||
src/music_kraken/database/song.py
|
||||
src/music_kraken/database/source.py
|
||||
src/music_kraken/database/target.py
|
||||
src/music_kraken/database/object_cache.py
|
||||
src/music_kraken/database/old_database.py
|
||||
src/music_kraken/database/read.py
|
||||
src/music_kraken/database/temp_database.py
|
||||
src/music_kraken/database/write.py
|
||||
src/music_kraken/lyrics/__init__.py
|
||||
src/music_kraken/lyrics/genius.py
|
||||
src/music_kraken/lyrics/lyrics.py
|
||||
src/music_kraken/metadata/__init__.py
|
||||
src/music_kraken/metadata/metadata_fetch.py
|
||||
src/music_kraken/metadata/metadata_search.py
|
||||
src/music_kraken/not_used_anymore/__init__.py
|
||||
src/music_kraken/not_used_anymore/fetch_audio.py
|
||||
src/music_kraken/not_used_anymore/fetch_source.py
|
||||
src/music_kraken/not_used_anymore/sources/__init__.py
|
||||
src/music_kraken/not_used_anymore/sources/genius.py
|
||||
src/music_kraken/not_used_anymore/sources/local_files.py
|
||||
src/music_kraken/not_used_anymore/sources/musify.py
|
||||
src/music_kraken/not_used_anymore/sources/source.py
|
||||
src/music_kraken/not_used_anymore/sources/youtube.py
|
||||
src/music_kraken/static_files/temp_database_structure.sql
|
||||
src/music_kraken/tagging/__init__.py
|
||||
src/music_kraken/tagging/song.py
|
||||
src/music_kraken/tagging/id3.py
|
||||
src/music_kraken/target/__init__.py
|
||||
src/music_kraken/target/set_target.py
|
||||
src/music_kraken/utils/__init__.py
|
||||
src/music_kraken/utils/functions.py
|
||||
src/music_kraken/utils/object_handeling.py
|
||||
src/music_kraken/utils/phonetic_compares.py
|
||||
src/music_kraken/utils/shared.py
|
||||
src/music_kraken/utils/shared.py
|
||||
src/music_kraken/utils/string_processing.py
|
||||
|
|
@ -1,2 +1,3 @@
|
|||
[console_scripts]
|
||||
music-kraken = music_kraken:cli
|
||||
|
||||
|
|
|
|||
|
|
@ -6,3 +6,7 @@ pydub~=0.25.1
|
|||
youtube_dl
|
||||
beautifulsoup4~=4.11.1
|
||||
pycountry~=22.3.5
|
||||
python-dateutil~=2.8.2
|
||||
pandoc~=2.3
|
||||
SQLAlchemy
|
||||
setuptools~=60.2.0
|
||||
|
|
|
|||
|
|
@ -0,0 +1 @@
|
|||
from music_kraken import objects
|
||||
|
|
@ -1,46 +0,0 @@
|
|||
import pycountry
|
||||
|
||||
from ..music_kraken.objects import (
|
||||
Song,
|
||||
Source,
|
||||
SourcePages,
|
||||
Target,
|
||||
Lyrics,
|
||||
Album
|
||||
)
|
||||
|
||||
"""
|
||||
TODO
|
||||
create enums for Album.album_status
|
||||
move country from Album to Artist, and use pycountry.Countries
|
||||
"""
|
||||
|
||||
song = Song(
|
||||
title="title",
|
||||
isrc="isrc",
|
||||
length=666,
|
||||
tracksort=1,
|
||||
genre="horrorcore",
|
||||
source_list=[
|
||||
Source(SourcePages.YOUTUBE, "https://www.youtube.com/watch?v=dQw4w9WgXcQ"),
|
||||
Source(SourcePages.SPOTIFY, "https://open.spotify.com/track/6rqhFgbbKwnb9MLmUQDhG6"),
|
||||
Source(SourcePages.BANDCAMP, "https://metalband.bandcamp.com/track/song1")
|
||||
],
|
||||
target=Target(file="song.mp3", path="~/Music"),
|
||||
lyrics_list=[
|
||||
Lyrics(text="some song lyrics", language="en")
|
||||
],
|
||||
album=Album(
|
||||
title="some album",
|
||||
label="braindead",
|
||||
album_status="official",
|
||||
language=pycountry.languages.get(alpha_2='de'),
|
||||
)
|
||||
)
|
||||
|
||||
|
||||
song1_sources = [
|
||||
Source(SourcePages.YOUTUBE, "https://www.youtube.com/watch?v=dQw4w9WgXcQ"),
|
||||
Source(SourcePages.SPOTIFY, "https://open.spotify.com/track/6rqhFgbbKwnb9MLmUQDhG6"),
|
||||
Source(SourcePages.BANDCAMP, "https://metalband.bandcamp.com/track/song1")
|
||||
]
|
||||
|
|
@ -0,0 +1,263 @@
|
|||
|
||||
import pycountry
|
||||
import unittest
|
||||
import sys
|
||||
import os
|
||||
|
||||
# Add the parent directory of the src package to the Python module search path
|
||||
sys.path.insert(0, os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
|
||||
|
||||
from music_kraken import objects
|
||||
|
||||
from music_kraken import metadata
|
||||
|
||||
|
||||
class TestSong(unittest.TestCase):
|
||||
|
||||
def setUp(self):
|
||||
self.song = objects.Song(
|
||||
genre="HS Core",
|
||||
title="Vein Deep in the Solution",
|
||||
length=666,
|
||||
isrc="US-S1Z-99-00001",
|
||||
tracksort=2,
|
||||
target=[
|
||||
objects.Target(file="song.mp3", path="example")
|
||||
],
|
||||
lyrics_list=[
|
||||
objects.Lyrics(
|
||||
text="these are some depressive lyrics", language="en"),
|
||||
objects.Lyrics(
|
||||
text="Dies sind depressive Lyrics", language="de")
|
||||
],
|
||||
source_list=[
|
||||
objects.Source(objects.SourcePages.YOUTUBE,
|
||||
"https://youtu.be/dfnsdajlhkjhsd"),
|
||||
objects.Source(objects.SourcePages.MUSIFY,
|
||||
"https://ln.topdf.de/Music-Kraken/")
|
||||
],
|
||||
album_list=[
|
||||
objects.Album(
|
||||
title="One Final Action",
|
||||
date=objects.ID3Timestamp(year=1986, month=3, day=1),
|
||||
language=pycountry.languages.get(alpha_2="en"),
|
||||
label_list=[
|
||||
objects.Label(name="an album label")
|
||||
],
|
||||
source_list=[
|
||||
objects.Source(objects.SourcePages.ENCYCLOPAEDIA_METALLUM,
|
||||
"https://www.metal-archives.com/albums/I%27m_in_a_Coffin/One_Final_Action/207614")
|
||||
]
|
||||
),
|
||||
],
|
||||
main_artist_list=[
|
||||
objects.Artist(
|
||||
name="I'm in a coffin",
|
||||
source_list=[
|
||||
objects.Source(
|
||||
objects.SourcePages.ENCYCLOPAEDIA_METALLUM,
|
||||
"https://www.metal-archives.com/bands/I%27m_in_a_Coffin/127727"
|
||||
)
|
||||
]
|
||||
),
|
||||
objects.Artist(name="some_split_artist")
|
||||
],
|
||||
feature_artist_list=[
|
||||
objects.Artist(
|
||||
name="Ruffiction",
|
||||
label_list=[
|
||||
objects.Label(name="Ruffiction Productions")
|
||||
]
|
||||
)
|
||||
],
|
||||
)
|
||||
|
||||
def test_song_genre(self):
|
||||
self.assertEqual(self.song.genre, "HS Core")
|
||||
|
||||
def test_song_title(self):
|
||||
self.assertEqual(self.song.title, "Vein Deep in the Solution")
|
||||
|
||||
def test_song_length(self):
|
||||
self.assertEqual(self.song.length, 666)
|
||||
|
||||
def test_song_isrc(self):
|
||||
self.assertEqual(self.song.isrc, "US-S1Z-99-00001")
|
||||
|
||||
def test_song_tracksort(self):
|
||||
self.assertEqual(self.song.tracksort, 2)
|
||||
|
||||
def test_song_target(self):
|
||||
self.assertEqual(self.song.target[0].file, "song.mp3")
|
||||
self.assertEqual(self.song.target[0].path, "example")
|
||||
|
||||
def test_song_lyrics(self):
|
||||
self.assertEqual(len(self.song.lyrics_list), 2)
|
||||
self.assertEqual(
|
||||
self.song.lyrics_list[0].text, "these are some depressive lyrics")
|
||||
self.assertEqual(self.song.lyrics_list[0].language, "en")
|
||||
self.assertEqual(
|
||||
self.song.lyrics_list[1].text, "Dies sind depressive Lyrics")
|
||||
self.assertEqual(self.song.lyrics_list[1].language, "de")
|
||||
|
||||
def test_song_source(self):
|
||||
self.assertEqual(len(self.song.source_list), 2)
|
||||
self.assertEqual(
|
||||
self.song.source_list[0].page, objects.SourcePages.YOUTUBE)
|
||||
self.assertEqual(
|
||||
self.song.source_list[0].url, "https://youtu.be/dfnsdajlhkjhsd")
|
||||
self.assertEqual(
|
||||
self.song.source_list[1].page, objects.SourcePages.MUSIFY)
|
||||
|
||||
|
||||
class TestAlbum(unittest.TestCase):
|
||||
|
||||
def setUp(self):
|
||||
self.album = objects.Album(
|
||||
title="One Final Action",
|
||||
date=objects.ID3Timestamp(year=1986, month=3, day=1),
|
||||
language=pycountry.languages.get(alpha_2="en"),
|
||||
label_list=[
|
||||
objects.Label(name="an album label")
|
||||
],
|
||||
source_list=[
|
||||
objects.Source(objects.SourcePages.ENCYCLOPAEDIA_METALLUM,
|
||||
"https://www.metal-archives.com/albums/I%27m_in_a_Coffin/One_Final_Action/207614")
|
||||
]
|
||||
)
|
||||
|
||||
def test_album_title(self):
|
||||
self.assertEqual(self.album.title, "One Final Action")
|
||||
|
||||
def test_album_date(self):
|
||||
self.assertEqual(self.album.date.year, 1986)
|
||||
self.assertEqual(self.album.date.month, 3)
|
||||
self.assertEqual(self.album.date.day, 1)
|
||||
|
||||
def test_album_language(self):
|
||||
self.assertEqual(self.album.language.alpha_2, "en")
|
||||
|
||||
def test_album_label(self):
|
||||
self.assertEqual(self.album.label_collection[0].name, "an album label")
|
||||
|
||||
def test_album_source(self):
|
||||
sp = self.album.source_collection.get_sources_from_page(objects.SourcePages.ENCYCLOPAEDIA_METALLUM)[0]
|
||||
|
||||
self.assertEqual(
|
||||
sp.page_enum, objects.SourcePages.ENCYCLOPAEDIA_METALLUM)
|
||||
self.assertEqual(
|
||||
sp.url, "https://www.metal-archives.com/albums/I%27m_in_a_Coffin/One_Final_Action/207614")
|
||||
|
||||
|
||||
class TestCollection(unittest.TestCase):
|
||||
|
||||
def setUp(self):
|
||||
self.collection = objects.collection.Collection(
|
||||
title="A collection",
|
||||
date=objects.ID3Timestamp(year=1986, month=3, day=1),
|
||||
language=pycountry.languages.get(alpha_2="en"),
|
||||
label_list=[
|
||||
objects.Label(name="a collection label")
|
||||
],
|
||||
source_list=[
|
||||
objects.Source(objects.SourcePages.ENCYCLOPAEDIA_METALLUM,
|
||||
"https://www.metal-archives.com/collections/I%27m_in_a_Coffin/One_Final_Action/207614")
|
||||
]
|
||||
)
|
||||
|
||||
def test_collection_title(self):
|
||||
self.assertEqual(self.collection, "A collection")
|
||||
|
||||
def test_collection_date(self):
|
||||
self.assertEqual(self.collection.date.year, 1986)
|
||||
self.assertEqual(self.collection.date.month, 3)
|
||||
self.assertEqual(self.collection.date.day, 1)
|
||||
|
||||
def test_collection_language(self):
|
||||
self.assertEqual(self.collection.language.alpha_2, "en")
|
||||
|
||||
def test_collection_label(self):
|
||||
self.assertEqual(
|
||||
self.collection.label_list[0].name, "a collection label")
|
||||
|
||||
def test_collection_source(self):
|
||||
self.assertEqual(
|
||||
self.collection.source_list[0].page, objects.SourcePages.ENCYCLOPAEDIA_METALLUM)
|
||||
self.assertEqual(
|
||||
self.collection.source_list[0].url, "https://www.metal-archives.com/collections/I%27m_in_a_Coffin/One_Final_Action/207614")
|
||||
|
||||
|
||||
class TestFormattedText(unittest.TestCase):
|
||||
def setUp(self):
|
||||
self.text_markdown = objects.FormattedText(markdown="""
|
||||
# This is a test title
|
||||
This is a test paragraph
|
||||
## This is a test subtitle
|
||||
- This is a test list item
|
||||
- This is another test list item
|
||||
This is another test paragraph
|
||||
""")
|
||||
self.text_html = objects.FormattedText(html="""
|
||||
<h1>This is a test title</h1>
|
||||
<p>This is a test paragraph</p>
|
||||
<h2>This is a test subtitle</h2>
|
||||
<ul>
|
||||
<li>This is a test list item</li>
|
||||
<li>This is another test list item</li>
|
||||
</ul>
|
||||
<p>This is another test paragraph</p>""")
|
||||
|
||||
self.plaintext = objects.FormattedText(plaintext="""
|
||||
This is a test title
|
||||
This is a test paragraph
|
||||
This is a test subtitle
|
||||
- This is a test list item
|
||||
- This is another test list item
|
||||
This is another test paragraph""")
|
||||
|
||||
def test_formatted_text_markdown_to_html(self):
|
||||
self.assertEqual(self.text_markdown.get_html(), self.text_html.html)
|
||||
|
||||
def test_formatted_text_html_to_markdown(self):
|
||||
self.assertEqual(self.text_html.get_markdown(), self.text_markdown)
|
||||
|
||||
def test_formatted_text_markdown_to_plaintext(self):
|
||||
self.assertEqual(self.text_markdown.get_plaintext(), self.plaintext)
|
||||
|
||||
def test_formatted_text_html_to_plaintext(self):
|
||||
self.assertEqual(self.text_html.get_plaintext(), self.plaintext)
|
||||
|
||||
|
||||
class TestLyrics(unittest.TestCase):
|
||||
|
||||
def setUp(self):
|
||||
self.lyrics = objects.Lyrics(
|
||||
text="these are some depressive lyrics",
|
||||
language=pycountry.languages.get(alpha_2="en"),
|
||||
source_list=[
|
||||
objects.Source(objects.SourcePages.ENCYCLOPAEDIA_METALLUM,
|
||||
"https://www.metal-archives.com/lyrics/I%27m_in_a_Coffin/One_Final_Action/207614"),
|
||||
objects.Source(objects.SourcePages.MUSIFY,
|
||||
"https://www.musify.com/lyrics/I%27m_in_a_Coffin/One_Final_Action/207614")
|
||||
]
|
||||
)
|
||||
|
||||
def test_lyrics_text(self):
|
||||
self.assertEqual(self.lyrics.text,
|
||||
"these are some depressive lyrics")
|
||||
|
||||
def test_lyrics_language(self):
|
||||
self.assertEqual(self.lyrics.language.alpha_2, "en")
|
||||
|
||||
def test_lyrics_source(self):
|
||||
self.assertEqual(len(self.lyrics.source_collection), 2)
|
||||
|
||||
|
||||
class TestMetadata(unittest.TestCase):
|
||||
|
||||
def setUp(self):
|
||||
self.timestamp = objects.ID3Timestamp(year=1986, month=3, day=1)
|
||||
self.metadata = objects.metadata.Metadata(id3_dict={"date": self.timestamp})
|
||||
|
||||
def test_metadata_id3(self):
|
||||
self.assertEqual(self.metadata.get_id3_value("date"), self.timestamp)
|
||||
|
|
@ -1,3 +1,3 @@
|
|||
from tests import example_data_objects
|
||||
from tests import test_objects
|
||||
|
||||
|
||||
|
|
|
|||
Loading…
Reference in New Issue